Robotics
The Evolution of Execution Management in rclcpp
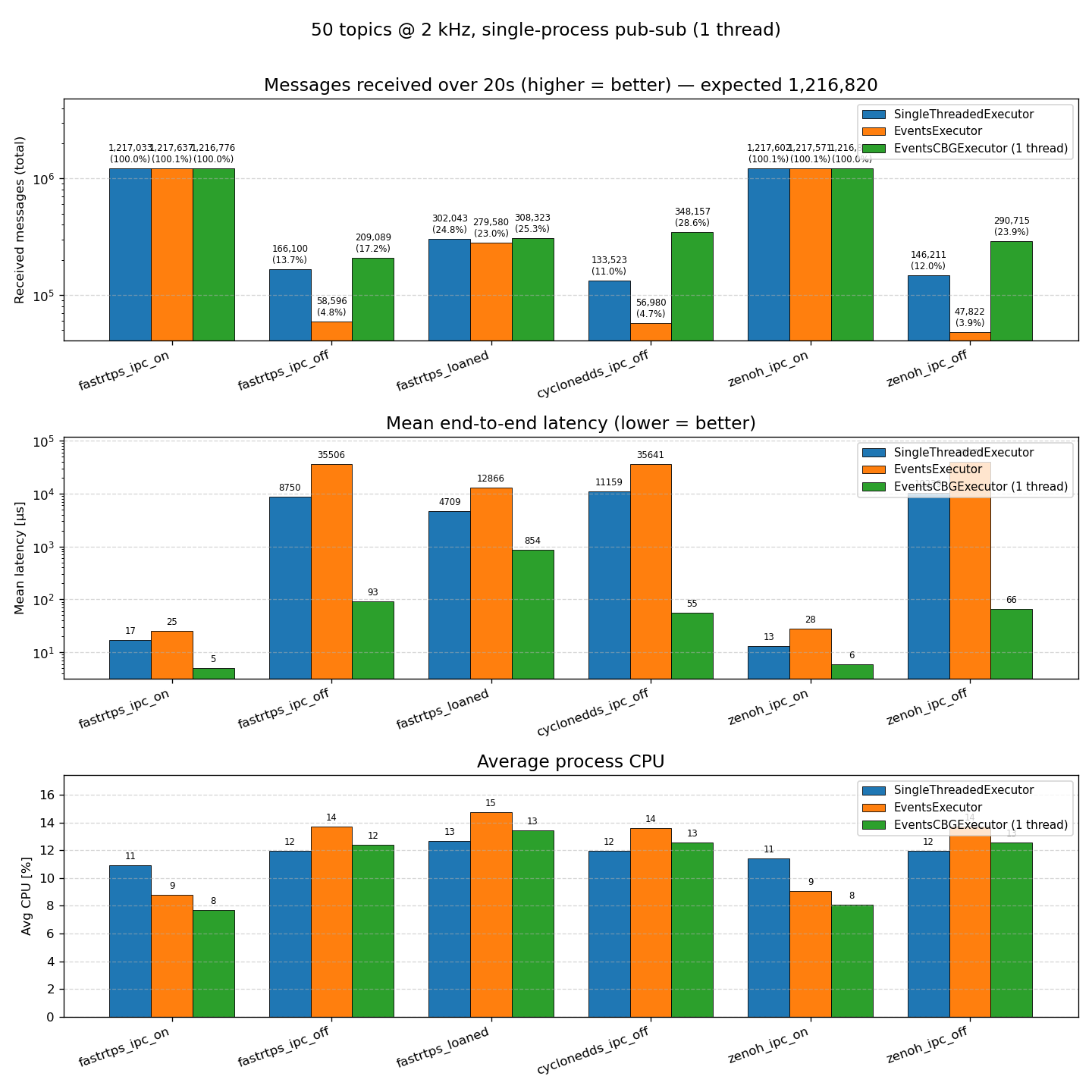
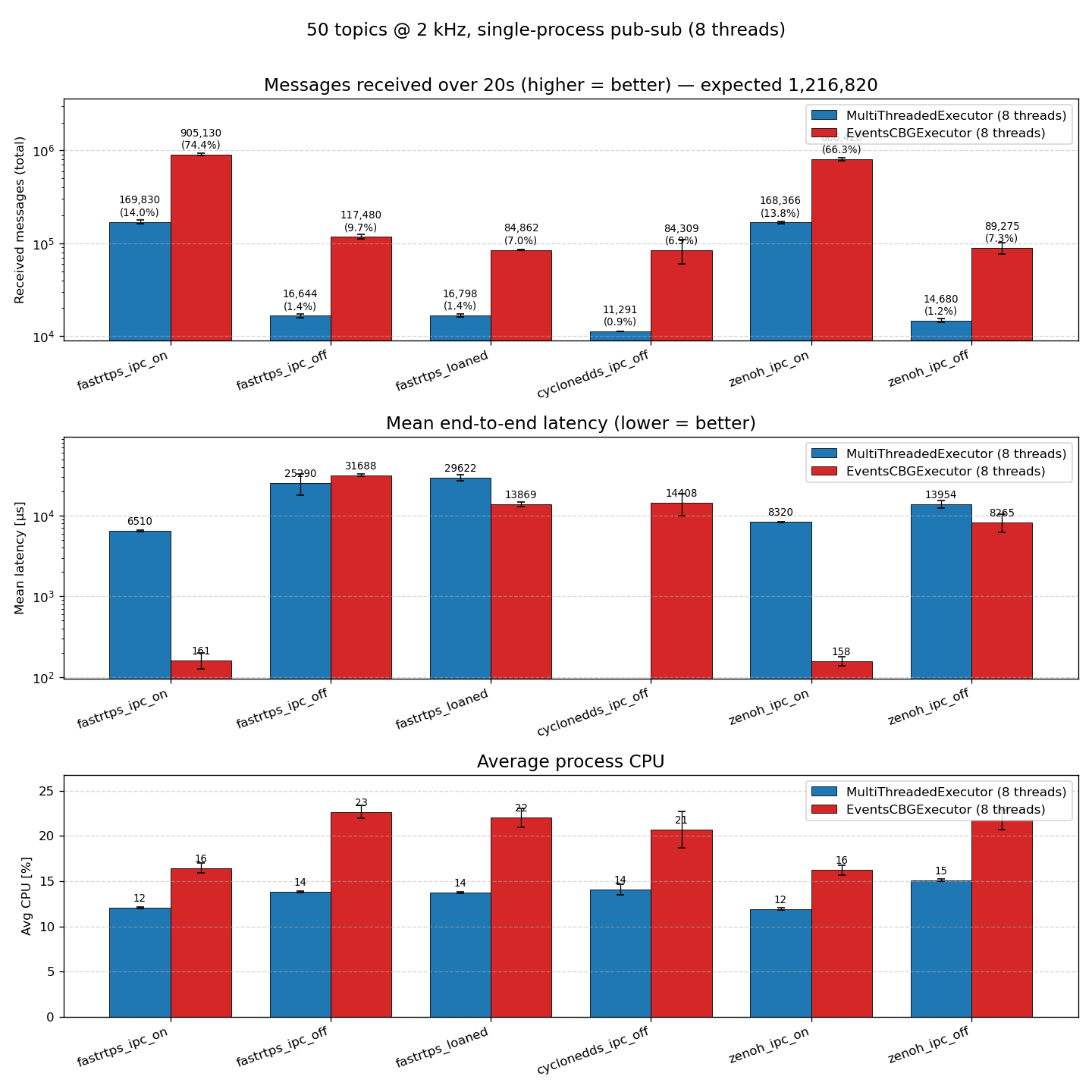
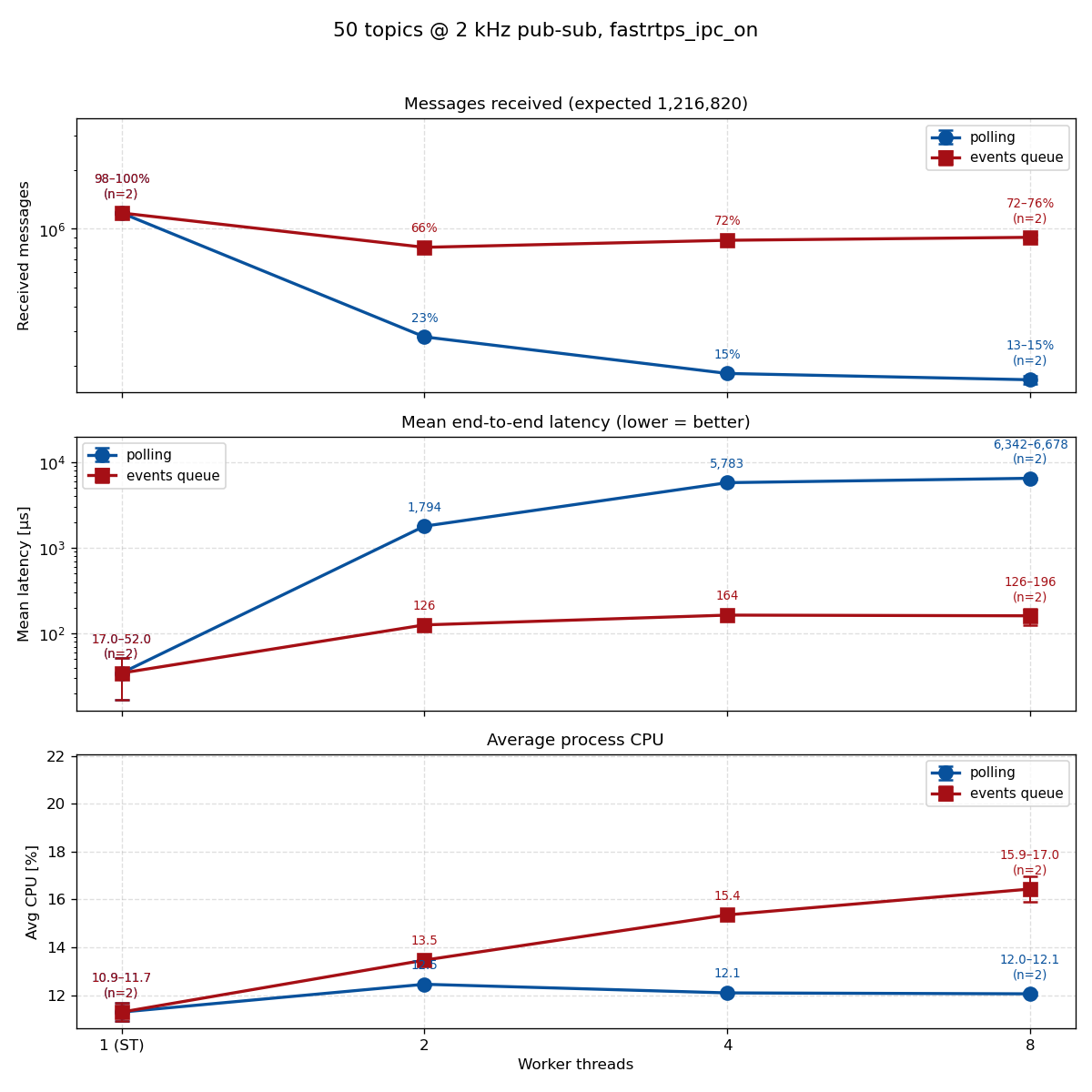
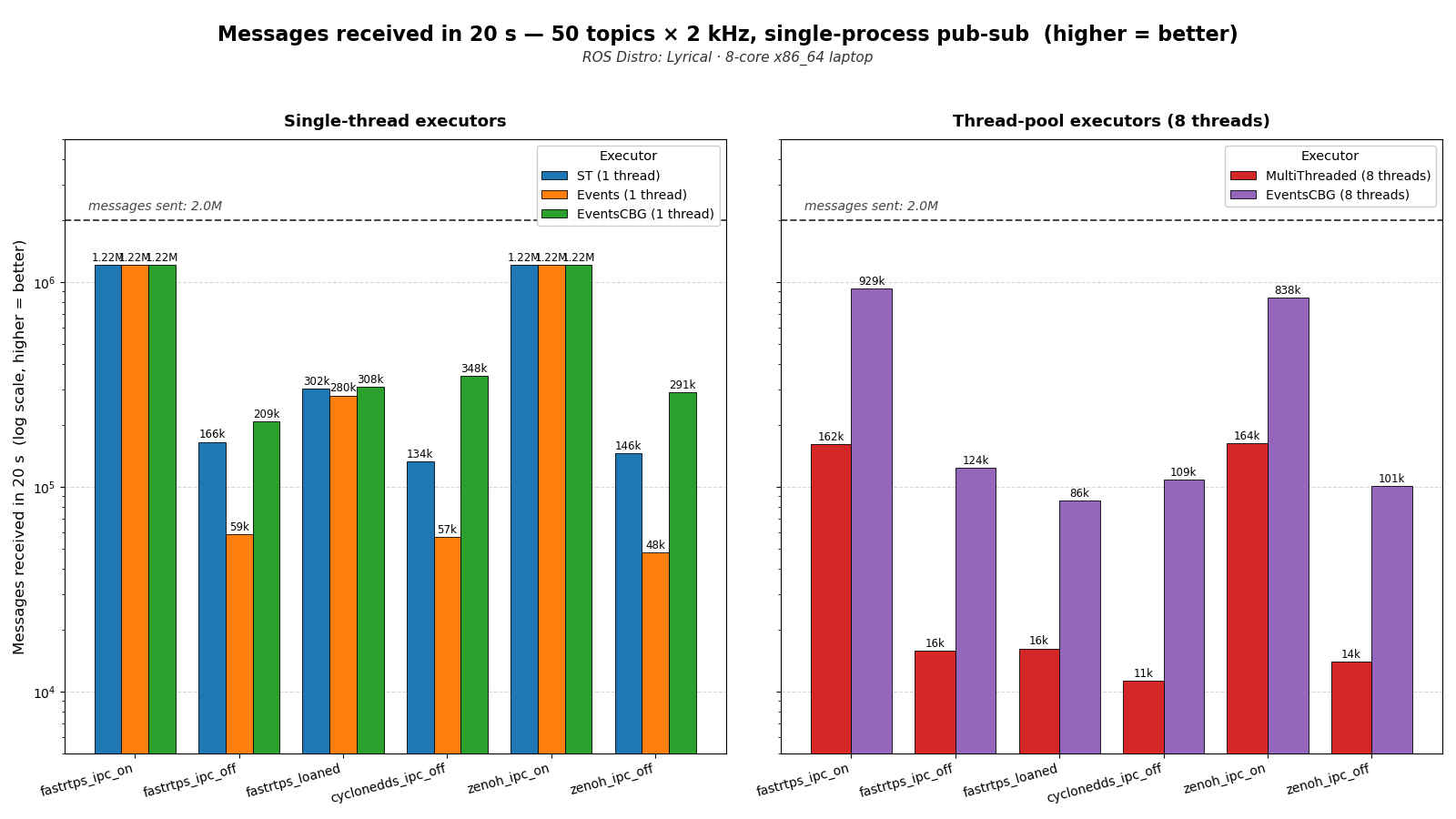
A tour through ROS 2's executor evolution—from the classic polling-based SingleThreaded and MultiThreaded executors to the new EventsCBGExecutor shipping in Lyrical Luth—with fresh benchmarks on throughput, latency, and CPU.

May 27, 2026
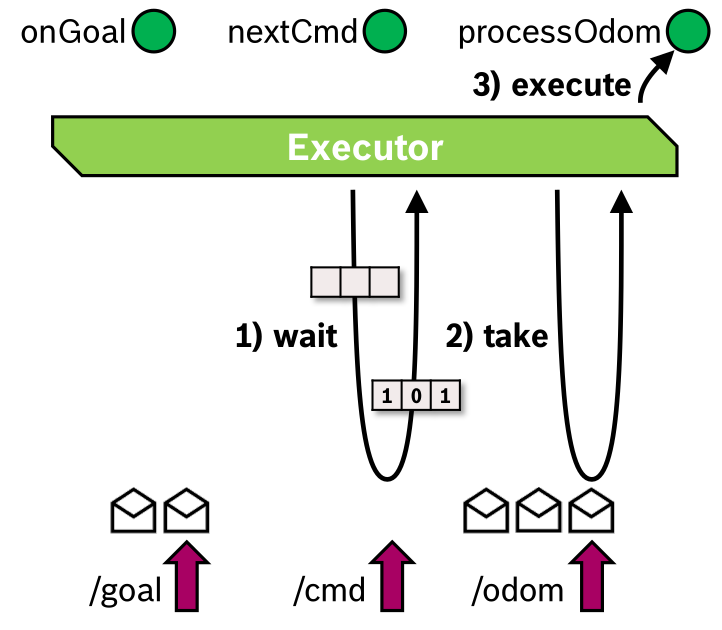
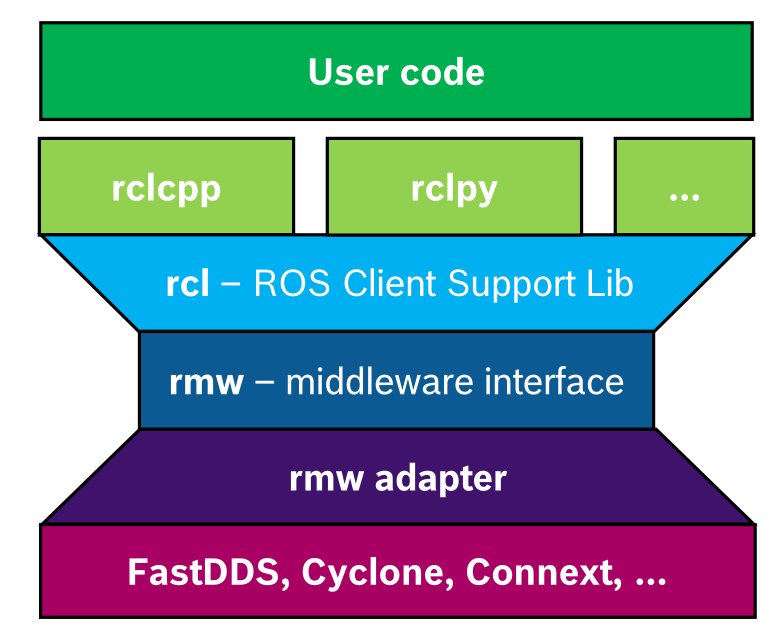
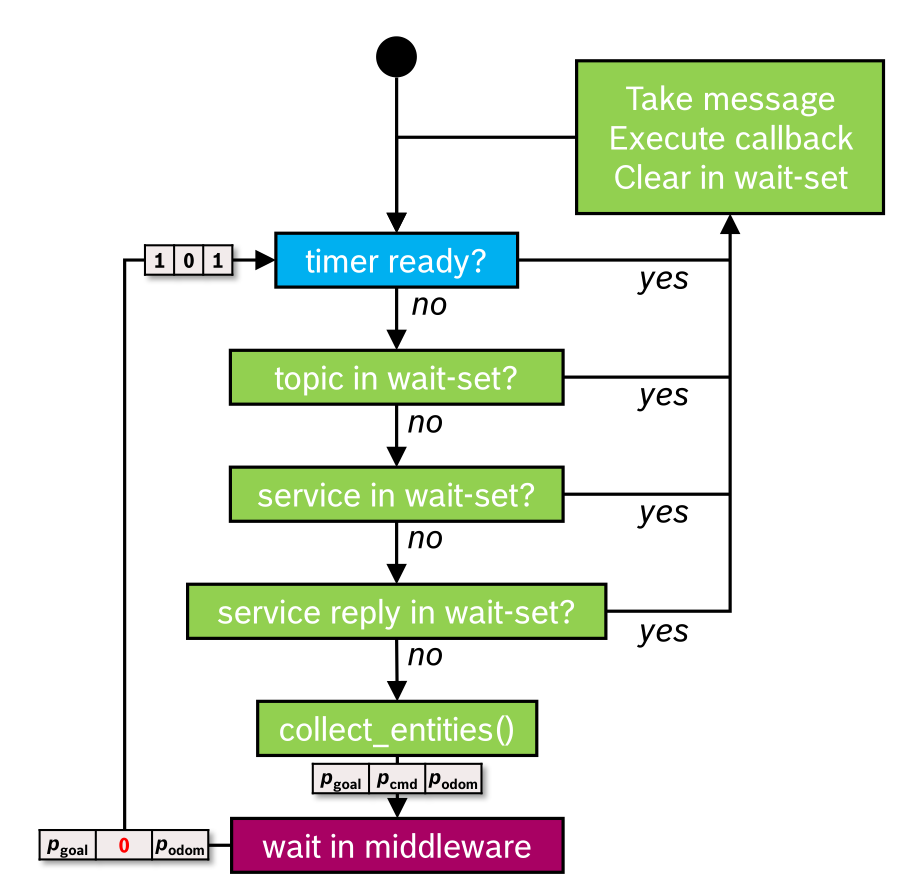
.png)
.png)
.png)
.png)
.png)
.png)